Turning a 7B LLM into a self-correcting code reasoner with /\/ Logikon
[TL;DR]
- We let Deepseek-Coder-7B (opens in a new tab) solve a code reasoning task (from CRUXEval (opens in a new tab)) that requires to predict a python function's output.
- Without Logikon, the LLM is not able to reliably self-correct by thinking through and revising its initial answers.
- Using
/\/Logikon (opens in a new tab), we can determine cases where the LLM struggles and a revision is most needed. - Filtering revisions with Logikon increases the self-correction accuracy from 30.9% to 43.1%.
Goal
We aim to test whether our /\/ Logikon (opens in a new tab) python demonstrator can improve the zero-shot code reasoning quality and self-correction ability in relatively small open LLMs.
Setup
Task
The output prediction task of the CRUXEval benchmark (opens in a new tab)1 requires to predict the output of a given python function by completing an assert test.
For example:
# sample 001 def f(nums): output = [] for n in nums: output.append((nums.count(n), n)) output.sort(reverse=True) return output assert f([1, 1, 3, 1, 3, 1]) == ???# sample 002 def f(a, b, c): result = {} for d in a, b, c: result.update(dict.fromkeys(d)) return result assert f((1, ), (1, ), (1, 2)) == ???
We've chosen this task because:
- code reasoning ability is key for LLM-based AI agents;
- code reasoning benefits from CoT prompting;2
- it is suited to test a LLM's ability to self-correct;
- its examples are relatively short, allowing us to stay within our computational budget.
We run our experiments on a random sample (N=200) of the CRUXEval test set.
AI Coding Expert
Deepseek-Coder-7b is a state-of-the-art open code LLM developed by Deepseek AI (published at 🤗: deepseek-coder-7b-instruct-v1.5 (opens in a new tab)).
Deepseek-Coder-7b outperforms the much bigger CodeLlama-34B (see here (opens in a new tab)).
We use Deepseek-Coder-7b as base model for implementing the self-correcting AI Coding Expert.
/\/ Critical Inquirer
We build a logic-checking system – a "Critical Inquirer" 🦉 – that analyses and evaluates complex natural language argumentation with our /\/ Logikon (opens in a new tab) python demonstrator. Emulating informal argumentation analysis, the Critical Inquirer rationally reconstructs a given argumentative text as a (fuzzy) argument map (opens in a new tab) and uses that map to score the quality of the original argumentation.
In a fuzzy argument map, support and attack relations are graded. The strength of support and attack relations is hence a natural indicator of an argumentation's (inferential) quality.
The /\/ Logikon (opens in a new tab) python demonstrator is model-agnostic and can be combined with different LLMs. The more powerful the LLM, the more capable and reliable the resulting self-check system. For computational reasons, we use the powerful 7B OpenChat 3.5 (opens in a new tab) model to build the Critical Inquirer.
Experiment
To test the ability of /\/ Logikon's metrics to improve an AI code reasoning system, we proceed in three steps:
Code completion
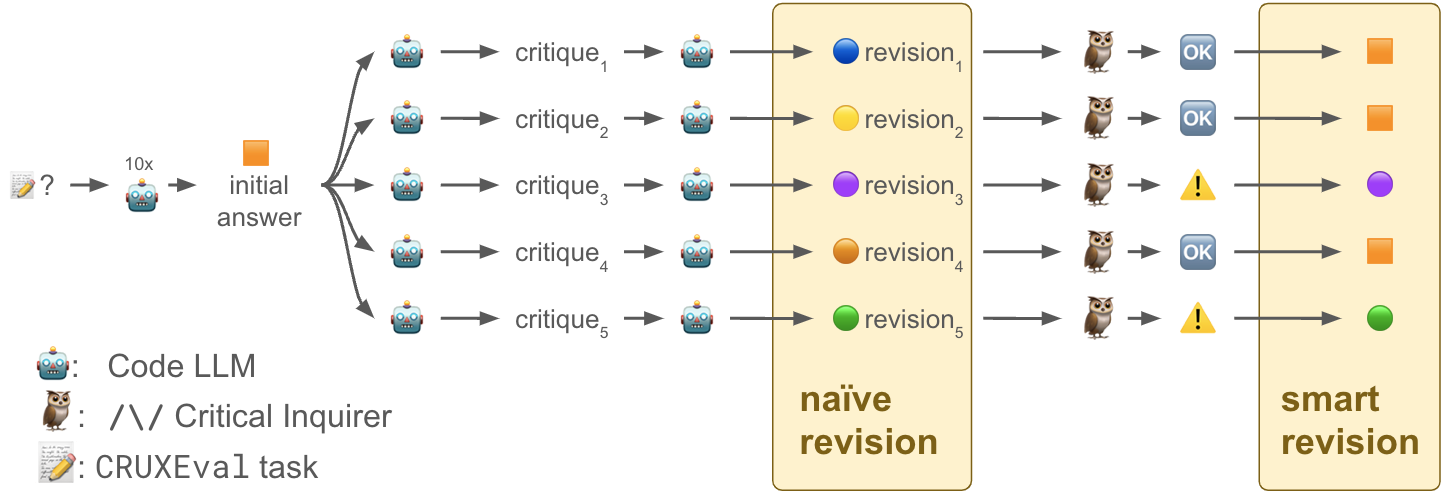
In step 1, we let the code LLM generate ten independent completions, and pick the most frequently generated output as the AI Coding Expert's initial answer.
Self-critique and naïve revision
In step 2, we ask the code LLM to critically discuss its initial answer (from step 1) and to revise it if necessary. For each example, we generate five different self-critiques (reasoning traces) by varying the temperature (0.1, 0.3, 0.5, 0.7, 0.95) and using the following prompt template:
Your task is to discuss whether a given code completion is correct.
Read the following code snippet and the given completion carefully.
Code snippet:
{code_snippet}
Completion:
{completion}
Discuss carefully whether the code completion ensures that the assert
test is passed. If possible, identify plausible objections which argue
that the assert fails.This gives us five revised answers for each example. In the naïve revision scenario, revisions always replace the original initial answer.
/\/ Logikon analysis and smart revision
In step 3, we use the Critical Inquirer 🦉 to logically reconstruct the reasoning (self-critique) generated in step 2. More specifically, each reasoning trace is reconstructed as an argument map.
We simply use the size of the argument map (number of nodes and edges) as indicator that the initial answer is actually in need of revision. We therefore filter and keep revisions that result from substantial discussions (more than 15 nodes and edges), replacing the initial answers with these select revisions only, and discard all the other revisions. That's what we call smart revision.
All experiments are zero-shot, i.e., there are no in-context demonstrations. The following figure illustrates the three steps of our experiment:
Results
We can now assess the effectiveness of the code LLM's self-critique with and without /\/ Logikon by comparing the accuracy of naïve and smart revisions:
| Naïve revision | Smart revision | |
|---|---|---|
Uses 🦉 & /\/ | ❌ | ✅ |
| Accuracy (abs) | 30.9 | 41.2 |
| Accuracy (rel) | -10.1 | +0.2 |
The relative accuracy reported in the table is calculated with respect to the accuracy of the initial (unrevised) answers.
Applying 🦉 & /\/ filtering, we keep roughly 5% of all revisions. We have checked that, by using argument map size as indicator, we're not simply tracking the length of self-critique traces: Selecting 5% of the revisions that result from the longest reasoning traces actually decreases accuracy (abs) to 21.7.
Conclusion
We have shown that our /\/ Logikon (opens in a new tab) python demonstrator can substantially improve the self-check effectiveness in relatively small open code LLMs.
The different limitations which have constrained our experiments suggest that the potential for improving self-check ability in LLMs with /\/ Logikon is much greater than reported here:
- We have chosen a relatively small LLM without domain-specific expertise (i.e., code reasoning) for building the
/\/Critical Inquirer. A more powerful LLM would allow for a more capable and reliable self-check system. - The
/\/Critical Inquirer has been built with the off-the-shelf/\/Logikon (opens in a new tab) python package. Adapting that package to the specific reasoning domain (e.g., by prompt engineering) will likely further increase the effectiveness and reliability of the reasoning metrics produced. - The
/\/Critical Inquirer's analysis is only used to filter and select self-critique traces. Feeding the argument maps and reasoning metrics back into the code LLM's revision process may further increase the overall performance.
Appendix
Technical Details
vLLM(opens in a new tab) as inference engine for the Code LLMLMQL(opens in a new tab) withtransformersandflash-attention-2as backend for/\/Logikon- Single A6000 GPU with 48GB VRAM
Notes
Footnotes
-
Gu et al (2024): CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution. arXiv 2401.03065 (opens in a new tab). ↩
-
As demonstrated by Gu et al (2024) in their CRUXEval paper. ↩