Turning a 7B LLM into a better legal reasoner with /\/ Logikon
[TL;DR]
- We let a 7B-LLM (OpenChat (opens in a new tab)) solve a legal task (from LegalBench (opens in a new tab)) that requires to determine whether a given claim is covered under an insurance policy.
- In our baseline scenario without CoT, the LLM is overconfident and totally fails to detect ambiguous cases.
- Using CoT prompting, the LLM starts classifying cases as ambiguous, but accuracy drops significantly.
- With
/\/Logikon (opens in a new tab), we can filter and select quality CoT traces, which increases the above-random-baseline accuracy of CoT by up to 80%, while retaining the ability to detect ambiguous cases.
Goal
We aim to test whether our /\/ Logikon (opens in a new tab) python demonstrator can improve the zero-shot reasoning quality in relatively small open LLMs.
Setup
Task
The insurance_policy_interpretation task of the LegalBench suite (opens in a new tab)1 requires to determine whether a given claim is covered under an insurance policy. The task is formulated as a ternary classification problem, where the classes are A: yes, B: no, and C: ambiguous.
For example:
- Policy: Denise's insurance covers damage from "House Removal," defined as "damage to belongings caused while being removed by professional removal contractors from the home."
Claim: Denise is moving to a new home on the other side of town. She asks her uncle, a retired professional mover, to help move her belongings out of her current home. During the move, her uncle's truck is involved in a minor accident that damages several pieces of her furniture and other belongings. Denise files a claim with her insurance company for the damage to her belongings.
Answer: B (not covered)- Policy: Harper's insurance covers damage from "House Removal," which includes "damage to belongings that occurs while being stored by professional removal contractors."
Claim: Harper is moving to a new home on the other side of town. Because her old home has already sold and her new home is not yet ready for her to move in, she checks into a hotel and asks a professional moving company to store some of her belongings at the company warehouse. A couple days before she is set to move in, the warehouse floods, which ruins the items that the movers were storing for Harper. Harper files a claim with her insurance company for the damage to her belongings.
Answer: A (covered)
We've chosen this task because:
- it is a real-world legal task;
- it may benefit from CoT prompting;
- it is suited to test a LLM's ability to navigate ambiguity and uncertainties;
- its examples are relatively short, allowing us to stay within our computational budget.
Legal AI Expert
OpenChat 3.5 is a state-of-the-art 7B-parameter LLM based on Mistral 7B and published under the Apache 2.0 license (at 🤗: openchat/openchat_3.5 (opens in a new tab)).
In our internal CoT LeaderBoard (to-be-published soon 🤞), OpenChat 3.5 has shown very strong CoT performance.
We use OpenChat 3.5 as base model for implementing the Legal AI Expert who must solve the LegalBench insurance_policy_interpretation task.
/\/ Critical Inquirer
We build a logical self-check system – a "Critical Inquirer" 🦉 – that analyses and evaluates complex natural language argumentation with our /\/ Logikon (opens in a new tab) python demonstrator. Emulating informal argumentation analysis, the Critical Inquirer rationally reconstructs a given argumentative text as a (fuzzy) argument map (opens in a new tab) and uses that map to score the quality of the original argumentation.
In a fuzzy argument map, support and attack relations are graded. The strength of support and attack relations is hence a natural indicator of an argumentation's (inferential) quality.
The /\/ Logikon (opens in a new tab) python demonstrator is model-agnostic and can be combined with different LLMs. The more powerful the LLM, the more capable and reliable the resulting self-check system. For computational reasons, we use – again – the 7B OpenChat 3.5 (opens in a new tab) model to build the Critical Inquirer.
Experiments
We run three experiments to test the ability of /\/ Logikon's reasoning metrics to improve an AI reasoning system: a baseline without CoT, a CoT prompting scenario, and a CoT prompting scenario with /\/ Logikon self-check. All experiments are zero-shot, i.e., there are no in-context demonstrations.
#1 No CoT
In the first experiment, the Legal AI Expert (OpenChat LLM) generates direct answers for the insurance_policy_interpretation task without any CoT prompting. The prompt template reads:
Your task is to determine whether an insurance claim is covered under
an insurance policy.
Read the following insurance policy and the insurance claim carefully.
Policy: {policy}
Claim: {claim}
Which of the following answers is correct?
A: Yes, the claim is covered under the policy.
B: No, the claim is not covered under the policy.
C: It's ambiguous.
Just answer with A, B, or C.#2 CoT Prompting
In the second experiment, we ask the Legal AI Expert to generate CoT reasoning traces for the insurance_policy_interpretation task. We generate for each policy-claim pair five different CoT traces by varying the temperature (0.1, 0.3, 0.5, 0.7, 0.95) and use the following prompt template:
Your task is to discuss whether an insurance claim is covered under
an insurance policy.
Read the following insurance policy and the insurance claim carefully.
Policy: {policy}
Claim: {claim}
Identify the different pros and cons for why the claim may, or may
not, be covered under the policy. Don't give a definite answer yet.The generated CoT traces can the be shown to the Legal AI Expert when solving the insurance_policy_interpretation task:
Your task is to determine whether an insurance claim is covered under
an insurance policy.
Read the following insurance policy and the insurance claim carefully.
Policy: {policy}
Claim: {claim}
Let's think step by step:
{cot_trace}
So, which of the following answers is correct in view of the above
reasoning?
A: Yes, the claim is covered under the policy.
B: No, the claim is not covered under the policy.
C: It's ambiguous.
Just answer with A, B, or C.#3 CoT Prompting with /\/ Logikon
In the third experiment, we use the /\/ Critical Inquirer to analyse & evaluate the CoT reasoning traces produced in the second experiment, which allows us to filter and select the best CoT traces according to /\/ Logikon's reasoning metrics.
More specifically, we devise two sub-experiments as depicted below:

#3a. In a first step, we only keep CoT traces whose rational reconstructions (fuzzy argument maps) have a sufficiently great minimum attack and support strength (≥70th percentile). Other CoT traces are discarded, in which case the AI reasoner solves the task without CoT.
#3b. In a second step, we filter CoT traces as in #3a but, in addition, choose from the remaining CoT traces and for each policy-claim pair the reasoning trace with the highest average reason strength.
The selected CoT traces are used to solve the insurance_policy_interpretation task. The prompt template is the same as in the second experiment, but the CoT traces are filtered and selected by the /\/ Critical Inquirer.
Results
Without CoT, the Legal AI Expert is overconfident and totally fails to detect ambiguous cases.
Not a single example is classified (correctly or incorrectly) as ambiguous if the Legal AI Expert directly answers the insurance_policy_interpretation questions without using CoT (experiment #1). The average accuracy (f1-score with micro aggregation) is 47.4% (or 14.1 points above the random baseline of 33.3%).
Can CoT prompting help to reduce the AI's overconfidence? Yes, but at a cost:
With CoT, the Legal AI Expert classifies cases as ambiguous way too often, leading to a loss of accuracy.
With CoT (experiment #2), between a third and a half of all examples are classified as ambiguous. CoT apparently makes the LLM "aware" of potential uncertainties. Overconfidence is not an issue anymore.
Yet the accuracy drops – depending on the CoT decoding regime – by up to 5 percentage points (and 2 percentage points on average, see also additional results) if the Legal AI Expert uses the CoT traces to solve the task. In the worst case, the Legal AI Expert performs just 9% above random baseline.
Now, by introducing /\/ Logikon to filter and select the CoT traces, we can improve the Legal AI Expert's performance significantly:
Filtering CoT traces with /\/ Critical Inquirer boosts the above-random-baseline accuracy by up to 80%. Selecting, in addition, the best reasoning trace with /\/ Critical Inquirer increases accuracy consistently compared to the No-CoT baseline, while retaining the ability to detect ambiguous cases.
Filtering CoT traces with /\/ Critical Inquirer (experiment #3a) raises the above-random-baseline accuracy by up to 8 percentage points, which amounts to a 80% relative increase of above-random-baseline accuracy compared to the CoT performance without /\/.
Selecting, in addition, the best reasoning trace with /\/ Critical Inquirer (experiment #3b) increases accuracy consistently by 2 percentage points compared to CoT without /\/.
As the following confusion matrices show, the Legal AI Expert is now able to detect ambiguous cases, while maintaining a high accuracy.
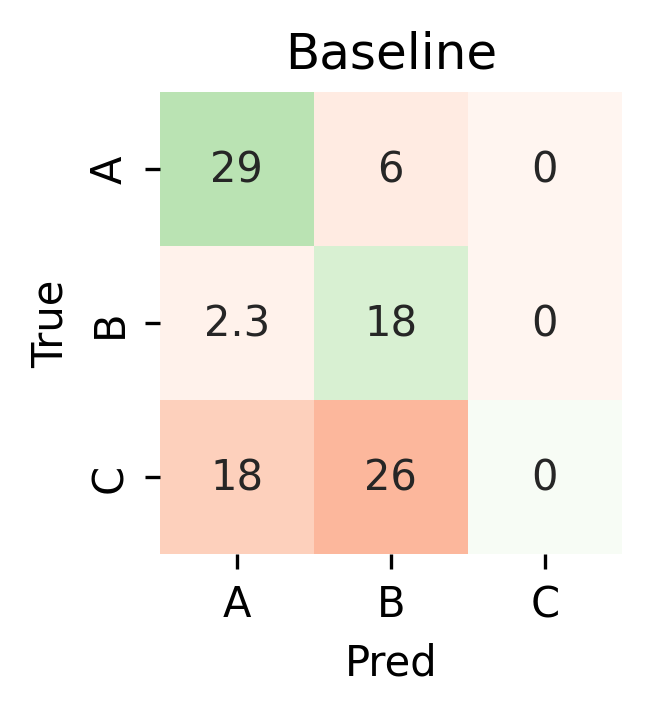 | 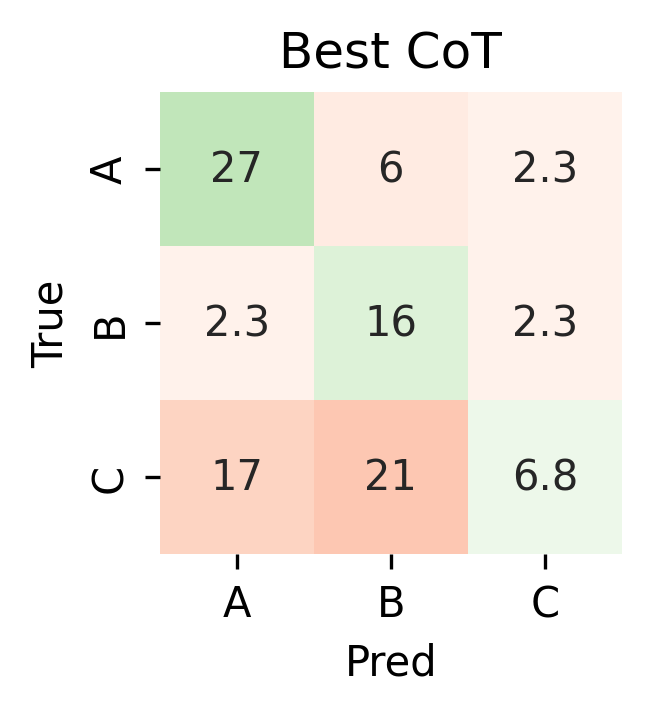 |
|---|
Confusion matrices for results of baseline (#1, left) and CoT with /\/ (#3b, right) experiments.
Conclusion
The following table summarizes the results of our experiments:
| System Design | Accuracy | No Overconfidence |
|---|---|---|
| No CoT | ➕ | ❌ |
| CoT | ➖ | ✅ |
CoT + /\/ 🏆 | ➕➕ | ✅ |
Without CoT, the Legal AI Expert is overconfident. CoT prompting resolves this problem, but at the cost of substantial accuracy reductions. By introducing /\/ Logikon to filter and select the CoT traces, we can enable the Legal AI Expert to manage ambiguities while increasing its overall performance.
We have shown that our /\/ Logikon (opens in a new tab) python demonstrator can improve the zero-shot reasoning quality in relatively small open LLMs.
The different limitations which have constrained our experiments suggest that the potential for improving reasoning quality in LLMs with /\/ Logikon is much greater than reported here:
- We have chosen a relatively small LLM for building the
/\/Critical Inquirer. A more powerful LLM would allow for a more capable and reliable self-check system. - On average, only one in four generated CoT traces meets the minimum quality criteria established by our
/\/Critical Inquirer. Having more CoT traces to choose from would likely increase the performance of the Legal AI Expert. - The
/\/Critical Inquirer has been built with the off-the-shelf/\/Logikon (opens in a new tab) python package. Adapting that package to the specific reasoning domain (e.g., by prompt engineering) will likely further increase the effectiveness and reliability of the reasoning metrics produced. - Our
/\/Critical Inquirer is measuring the inferential quality of a reasoning trace only. Including further dimensions of reasoning quality (e.g., presentation clarity, factual correctness) promises to boost the effectiveness of the/\/self-check system.
Appendix
Technical Details
vLLM(opens in a new tab) as inference engine for the Legal AI ExpertLMQL(opens in a new tab) withtransformersandflash-attention-2as backend for/\/Logikon- Single A6000 GPU with 48GB VRAM
Additional Results
Accuracies for CoT experiments without (#2) and with (#3a) /\/, reported for different CoT decoding strategies:
| CoT Decoding | Accuracy CoT (#2) | Accuracy CoT+🦉 (#3a) | Diff (#3a - #2) |
|---|---|---|---|
| temp=0.1 | (33.3 +) 17.8 | (33.3 +) 13.3 | -4.5 |
| temp=0.3 | (33.3 +) 11.1 | (33.3 +) 15.6 | +4.5 |
| temp=0.5 | (33.3 +) 9.6 | (33.3 +) 17.1 | ⚡️ +7.5 |
| temp=0.7 | (33.3 +) 15.6 | (33.3 +) 14.8 | -0.8 |
| temp=0.95 | (33.3 +) 10.3 | (33.3 +) 14.8 | +4.5 |
| any | (33.3 +) 12.9 | (33.3 +) 15.1 | +2.2 |
Confusion matrices for results of CoT (#2, top) and CoT with /\/ (#3a, bottom) experiments:
.d62fa06f.png) | .11fddf7e.png) | .73c48149.png) | .39226b15.png) | .626e401c.png) |
|---|---|---|---|---|
.326c0ba7.png) | .c4fafaaf.png) | .3885bf55.png) | .697e0516.png) | .b8b1343d.png) |
Notes
Footnotes
-
Guha et al (2023): LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models. arXiv 2308.11462 (opens in a new tab). Subtask contributed by Brandon Waldon, Zehua Li, and Megan Ma. ↩